
Amazon S3 Tables を AWS Glue 用いてNamespaceとテーブルの作成、データ追加・削除までやってみた #AWSreInvent
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
Amazon S3 Tables を AWS Glue 用いてNamespaceとテーブルの作成、データ追加・削除までやってみた
AWS事業本部コンサルティング部の石川です。S3 Tables の画面で「テーブルを作成、変更、削除するには、Amazon EMR を使用します」というメッセージを見たら、AWS Glueでできてもいいのでは?と思っていたところ、弊社にはData Firehoseを用いてデータを書き込むというアクロバティックなことをサクッとやってしまう漢がおりまして、私も負けないぞ、ということで挑戦してみました。
ということで、Glue 5.0のパッケージなどをこそこそと調べていたのが前日のブログになります。
Amazon S3 Tables を AWS Glue したい理由
私は実務者なので
- 巷の人たちが書いてる検証ブログのように、vanilla sparkでS3 Tablesが使えても実務で使える気がしない
- S3上のデータファイルをS3 Tables上のIcebergフォーマットのGlueテーブルにロードしたい
- 他のGlueテーブルと結合してデータマートを作成したい
そして、上記をフルマネージドサービスで実現したい、思ってしまうわけです。
AWS Glue でNamespaceとテーブルの作成、データ追加
以降の検証は、US East (N. Virginia) us-east-1 リージョンで実施しました。
マネジメントコンソールからテーブルバケットを作成
[Table buckets New ]のメニューを選び、[Create table bucket]を押します。
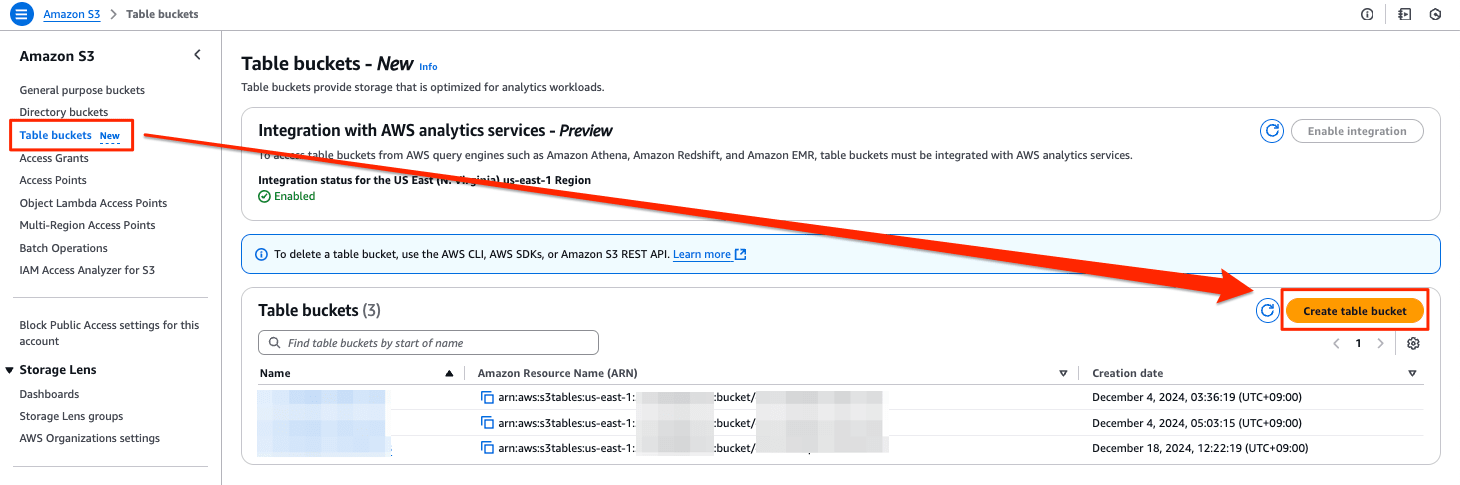
Table bucket nameを入力して、[Create table bucket]を押します。

Glue ETL ジョブの作成
S3 Tables用のランタイムのダウンロード
以下のリンクからダウンロードしてください。
s3-tables-catalog-for-iceberg-runtime-0.1.3.jar
ジョブの設定
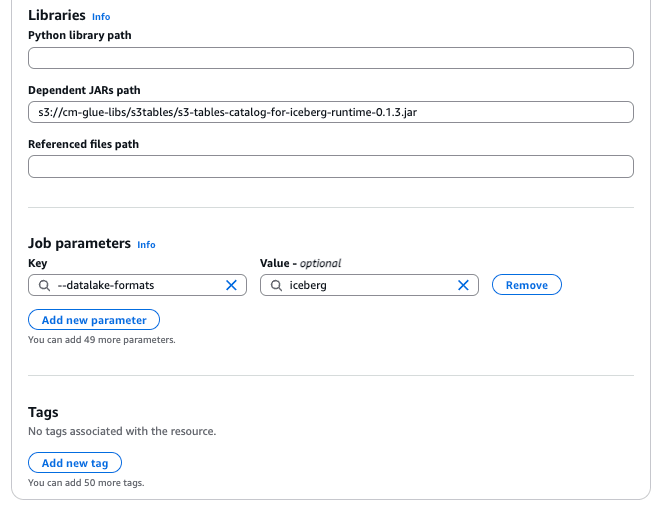
Job details タブの各項目に以下の設定を追加してください。
- Glue version: Glue 5.0
- Worker type: G 1X
- Requested number of workers: 2
- Dependent JARs path:
s3://<your_bucket>/<your_key>/s3-tables-catalog-for-iceberg-runtime-0.1.3.jar - Job parameters:
--datalake-formatsiceberg
ソースコード
Scriptタブに以下のコードをコピーします。warehouseには、作成したS3 Tablesのarnに変更してください。
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from pyspark.conf import SparkConf
warehouse = "arn:aws:s3tables:us-east-1:123456789012:bucket/cm-namespace-20241218"
conf = SparkConf()
conf.set("spark.sql.catalog.s3tablesbucket", "org.apache.iceberg.spark.SparkCatalog")
conf.set("spark.sql.catalog.s3tablesbucket.catalog-impl", "software.amazon.s3tables.iceberg.S3TablesCatalog")
conf.set("spark.sql.catalog.s3tablesbucket.warehouse", warehouse)
conf.set("spark.sql.extensions", "org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions")
sparkContext = SparkContext(conf=conf)
glueContext = GlueContext(sparkContext)
# Spark Session
spark = glueContext.spark_session
# Create namespace in S3 Tables
spark.sql( """ CREATE NAMESPACE IF NOT EXISTS s3tablesbucket.cm_namespace """)
# # Drop Table in S3 Tables
# spark.sql( """ DROP TABLE IF EXISTS s3tablesbucket.cm_namespace.`users` """)
# # But "Error Category: UNSUPPORTED_OPERATION_ERROR; Failed Line Number: 26; UnsupportedOperationException: S3 Tables does not support the dropTable operation with purge=false. Some versions of Spark always set this flag to false even when running DROP TABLE PURGE commands. You can retry with DROP TABLE PURGE or use the S3 Tables DeleteTable API to delete a table."
# Delete in S3 Tables
spark.sql( """ DELETE FROM s3tablesbucket.cm_namespace.`users` """)
# Create Table using Iceberg in S3 Tables
spark.sql( """ CREATE TABLE IF NOT EXISTS s3tablesbucket.cm_namespace.`users` (id INT, name STRING) USING iceberg """)
# Use Namespace
spark.sql( """ USE s3tablesbucket.cm_namespace """).show()
# Show Tables
spark.sql( """ SHOW TABLES """).show()
# Insert records into Iceberg table in S3 Tables
spark.sql( """ INSERT INTO s3tablesbucket.cm_namespace.`users` (id, name) VALUES(1, 'Alice')""" )
# Read from Iceberg table in S3 Tables
spark.sql(""" SELECT * FROM s3tablesbucket.cm_namespace.`users` """).show()
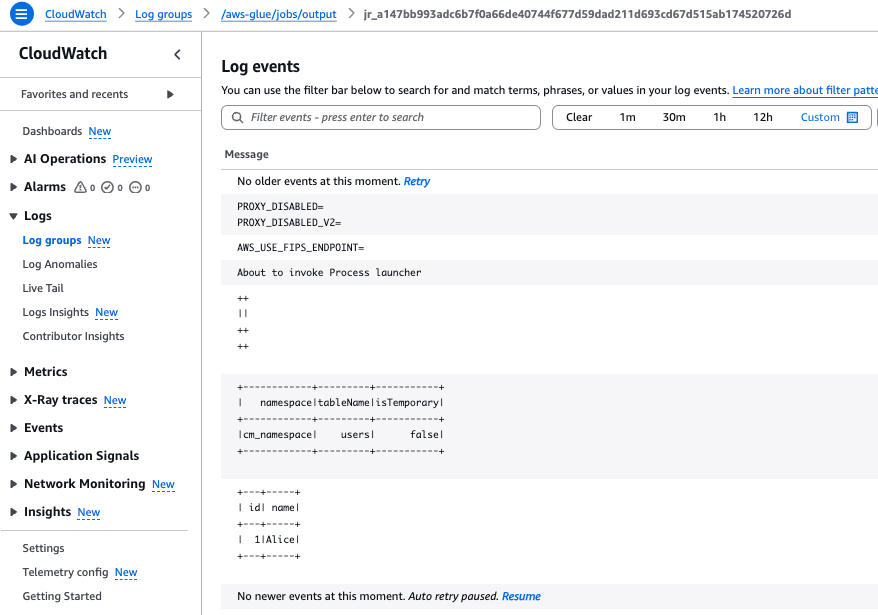
実行結果
テーブルが作成され、レコードが追加されていることが確認できます。
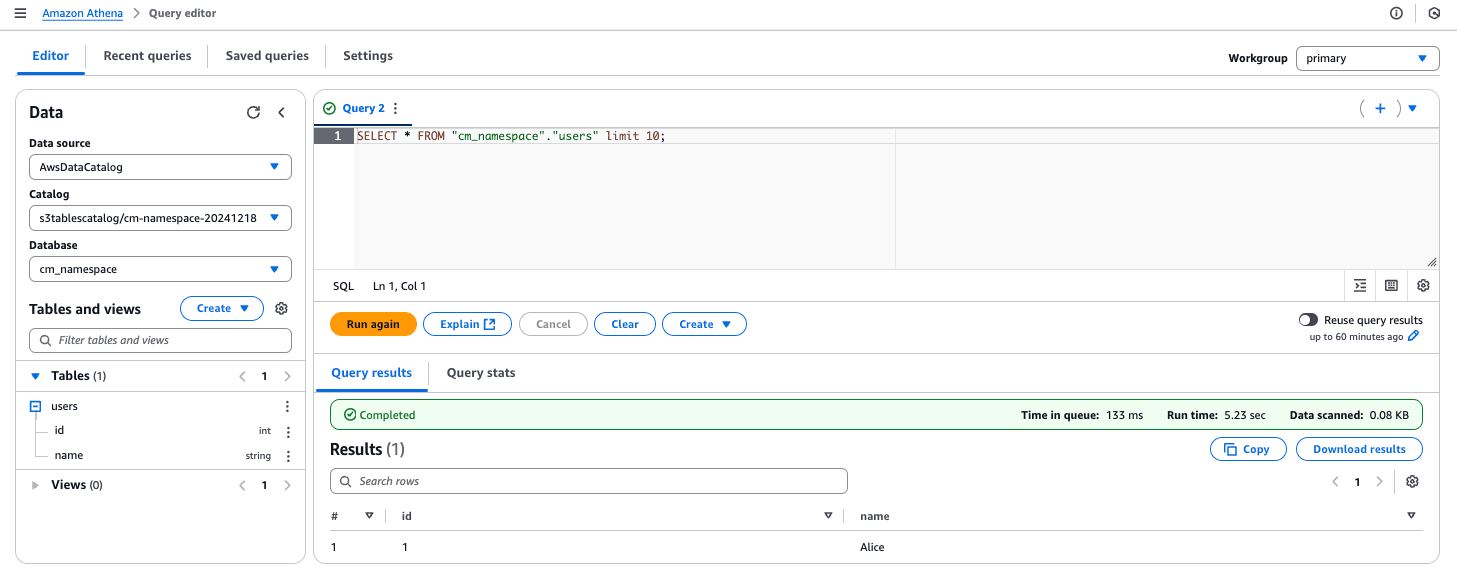
同様にAmazon Athenaのクエリエディタから同様に確認できました。
最後に
AWS Glueを使用してAmazon S3 Tablesでネームスペースとテーブルを作成し、データを追加・削除することは、S3上のデータファイルをIcebergフォーマットのGlueテーブルにロードし、他のGlueテーブルと結合してデータマートを作成するという実務的なニーズに応えるものです。
Glue 5.0のランタイムと特定の設定を使用することで、S3 Tablesの機能をフルマネージドサービスとして活用できることが示されました。
合わせて読みたい









